



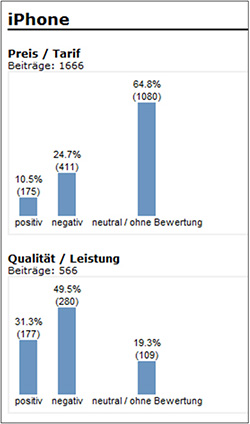
Beispiel für eine Tonalitätsanzeige aus der Software VICO Analytics.
Sind die Social-Media-Inhalte bewertet, gilt es, diese Inhalte darzustellen. Die Analyse der geflaggten Daten erfolgt auch deswegen, weil sie in Unternehmen häufig als Grundlage für Präsentationen und Entscheidungsfindungen verwendet wird. Die Darstellung der Ergebnisse kann je nach Indexierungsmethode unterschiedlich ausfallen. Die wichtigste Funktionalität einer grafischen Darstellung ist der Drill-Down. Er erlaubt, von der Grafik direkt auf die ausgewerteten Beiträge zuzugreifen und dient daher dem Qualitätsmanagement des Projekts.
Die Tonalitätsanalyse beschränkt sich gewöhnlicherweise nicht nur auf ein Medium, sondern deckt die Gesamtheit aller gefundenen Quellen (neben Foren und Blogs auch Twitter, Facebook, YouTube, Flickr etc.) ab. Nur so kann ein Unternehmen alle Kanäle auf relevante Inhalte prüfen. Ist ein Flagging-System auf nur eine Quelle beschränkt, ist auch die Analyse der Bewertungen nur etwa für Blogs möglich und lässt alle anderen Medien außer Acht. Eine derartig einseitige Sichtweise hätte den Nachteil, dass der Kunde nur einen Bruchteil der Meinungen aus Social Media zur Kenntnis nimmt. Ein flächendeckendes Meinungsbild kann auf diese Weise nicht gewonnen werden.
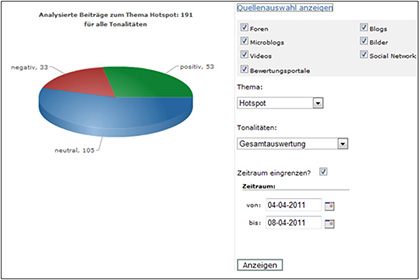
Ein weiteres Beispiel für die Darstellung von Tonalitäten (Quelle: VICO Analytics).
Tonalitätsverläufe

Die Auswertung von Tonalitäten mittels Flag-Analyse bietet den Vorteil, dass zeitliche Analysen möglich sind.
Die Ergebnisse dieser Messungen machen den wahrscheinlich größten Wert eines Monitorings aus, da erst Analysen in Relation zur Zeit in der Lage sind, Trends, Chancen und Risiken abzubilden, die im Social Web erwähnt werden.
Ein Tonalitätsverlauf wird jedoch weder für ein einziges Produkt noch als Gesamtübersicht aller Produkte erstellt, sondern beinhaltet die Möglichkeit, unter verschiedenen Produkten auszuwählen. Eine solche multidimensionale Betrachtung bietet dem Unternehmen Einblicke in den detaillierten Diskussionsverlauf der Themen zu einem seiner Produkte.
Drill Down
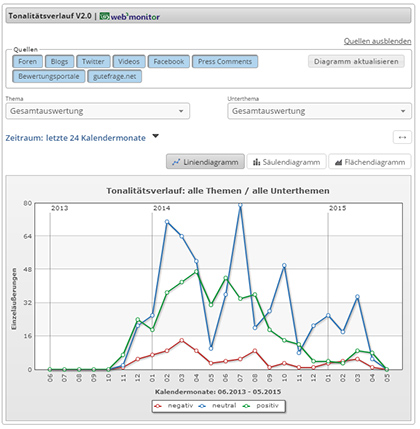
Tonalitätsverlauf zum Thema „Telefonanlagen“ und „Vertrag“ in einem Monitoring-System mit Drill-Down: „Alle Beiträge zum gewählten Thema anzeigen“ ist Bestandteil der Grafik (Quelle: VICO Analytics)
Per Drill-Down kann der Anwender nachvollziehen, welche Prinzipien bei der Bewertung der Social-Media-Beiträge angewendet wurden. So ermöglicht der Drill-Down die Qualitätskontrolle durch den Auftraggeber, der dem Monitoring-Anbieter sonst blind vertrauen müsste. Außerdem ist es nur mit einem Drill-Down möglich, die identifizierten Meinungsäußerungen im Kontext nachzuvollziehen.
Flagging

Ergebnisse, die mit der Suchmaschine gewonnen wurden, sind der erste Schritt des Social Media Monitoring. Die Bewertung dieser Resultate liefert den eigentlichen Mehrwert für ein Unternehmen.
Um diesen Vorgang zu unterstützen, werden Social-Media-Inhalte intellektuell, also von menschlichen Researchern, gesichtet. Sie können im Gegensatz zu einer automatischen Sentiment-Analyse nahezu fehlerfrei bewerten, da sie durch ihre eigene Intelligenz Sachinhalte besser nachzuvollziehen und einzuordnen vermögen. Zudem fällt die Problematik der Social Streams weg, bei der die Kommentare etwa zu einem Blogbeitrag in den meisten Fällen automatisch nicht mit diesem in Zusammenhang gebracht werden können. Im Gegensatz zur künstlichen Intelligenz automatischer Analyse-Systeme kann ein Mensch diese Verbindung erkennen. Eine Maschine ist außerdem kaum in der Lage, einem kurzen Posting ein Thema oder ein Sentiment zuzuordnen. Eine nicht unerhebliche Rolle spielen die signifikant hohe Menge an Rechtschreibfehlern, Abkürzungen und Netslang, die in Social Media üblich ist.
Intellektuelle Bewertung / Sentimentierung
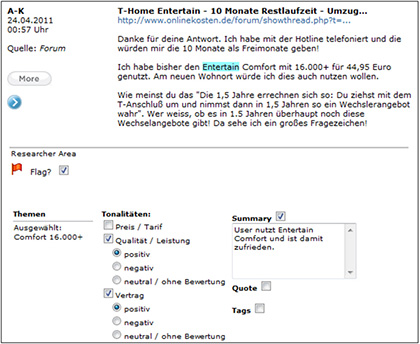
Im Flagging-System der Software VICO Analytics sieht man, dass einem Social-Media-Beitrag ein Thema und mehrere Tonalitäten bzw. Sentiments zugeordnet werden können.
Die intellektuelle Bewertung durch einen menschlichen Researcher wird häufig als Flagging bezeichnet. Dieses Prinzip erlaubt es dem Researcher der Monitoring-Agentur, Inhalte zu lesen, Themen darin zu erkennen und den Beiträgen Tonalitäten (also wertende Aussagen) zuzuordnen. Das System bietet eine Infrastruktur und Geschwindigkeit an, die eine Arbeitserleichterung für den Researcher darstellen. Grundsatz ist hier die Aufgabenangemessenheit.
Üblicherweise wird der Aufwand, intellektuell Social-Media-Inhalte zu bewerten, überschätzt. Sind die Grundsätze der Softwareergonomie erfolgreich umgesetzt, ist ein einziger Researcher in der Lage, täglich mehr als 800 Beiträge intellektuell zu bewerten. Durch die Möglichkeit, aus einer großen Datenmenge nur die relevanten Inhalte herauszufiltern, bleiben dem Researcher meist weit weniger Beiträge zur Bewertung übrig. Ein Beispiel verdeutlicht die Größenordnungen: Zwar erscheinen allein zum Thema „BMW“ monatlich mehr als 10.000 Beiträge in Social Media (Sen, 2010a), dennoch können durch komplexe Abfragen die Beiträge ausgewählt werden, die für das Unternehmen und das jeweilige Projekt tatsächlich relevant sind. Von 10.000 Beiträgen passen dann beispielsweise nur 300 auf die ausgewählten Kriterien: Diese können von einem Researcher kurzfristig und in wenigen Stunden ausgewertet werden. Solche Anwendungsmöglichkeiten bieten sich allerdings nur dann, wenn das Monitoring-System für komplexe Abfragen entwickelt und das Flagging-Modul effizient in den Research-Prozess eingebunden wurde.
Positiv, Negativ, Neutral
Attribute können über eine Administrationsoberfläche beliebig verändert und erweitert werden. Dabei ist es nicht nur wichtig, dass die Themenliste beliebig erweitert werden kann. Auch Tonalitäten sollten sich den Anforderungen anpassen und nicht nur „positiv“, „negativ“ und „neutral“ als Werturteile vorsehen. So können, je nach Ziel des Projekts, auch weitere Sentiments hinzugefügt werden. Möglich wären beispielsweise stilistische Tonalitäten wie „Boykottaufruf“, „Namensnennung“, „polemisch“ und natürlich viele weitere mehr. Schließlich hat jedes Unternehmen individuelle Anforderungen an ein Social Media Monitoring. Diese Anforderungen können sich zudem im Laufe eines Projekts im Sinne eines Lernprozesses verändern. Nicht veränderbare Attribute können daher dazu führen, dass dem Unternehmen nicht der optimale Mehrwert geliefert werden kann.
Die Universität Düsseldorf forscht bereits seit längerer Zeit im Bereich der intellektuellen Sentiment Analyse. Das System namens „Emotional Information Retrieval“ (EmIR) betreibt Tonalitätsanalysen nicht nur mit den Attributen „negativ“, „positiv“ und „neutral“, sondern zusätzlich mit Emotionen wie „Trauer“, „Freude“, „Sehnsucht“, „Ekel“ und „Liebe“ (Sen, 2010a). Das zeigt, wie vielfältig der Einsatz von Tools zur Tonalitätsanalyse sein kann, sofern diese eine derartige Flexibilität zulassen.
Export-Funktionen
Bietet das Monitoring-System die Bewertung von Beiträgen nicht innerhalb des Cockpits an, sind Ausweichmethoden erforderlich. Eine Möglichkeit wäre es, die gefundenen Social-Media-Daten durch einen Export in ein anderes System zu integrieren, um sie schließlich dort zu bewerten. Diese Methode bedeutet, dass zur Bewertung von Inhalten zwei Systeme eingesetzt werden müssten. Ein solches Vorgehen würde jedoch dem Prinzip der Simplicity und dem Grundgedanken der Effizienz widersprechen. Neben dem höheren Verwaltungsaufwand sind hier außerdem weitere Kostenfaktoren zu berücksichtigen.
Bei größeren Agenturen verfügt das System über eine schnelle und einfache Exportmöglichkeit und mindestens ein Flagging-Modul. Diesen liegen zudem Konzepte vor, nach welchen Social-Media-Inhalte bewertet werden.
Den richtigen Ton treffen mit der Tonalitätsanayse
Möglichkeiten und Grenzen

von Dominik Grimm
Sei es in Foren, Blogs oder Social Networks, im Web 2.0 wird überall publiziert, kommentiert und diskutiert. Insbesondere Internetforen machen einen maßgeblichen Anteil an der Meinungsbildung im Netz aus. In unzähligen Foren, die nahezu jeden Themenbereich abdecken, diskutieren allein im deutschsprachigen Raum täglich Millionen von Mitgliedern. Dabei werden Fragestellungen, Anmerkungen und Erfahrungsberichte zu Produkten und Dienstleistungen zum Teil auf sehr hohem Niveau ausgetauscht.
Unterschiedliche Studien belegen derzeit, dass der potentielle Kunde dieser Art der Kommunikation eine hohe Bedeutung zumisst und die Angaben in Foren als glaubwürdig erachtet. Viele Unternehmen haben bereits das Potential dieser frei verfügbaren Informationen erkannt und werten diese systematisch aus. Dabei haben sogenannte automatische Sentimentanalysen die Aufgabe, schnell und unkompliziert einen Überblick über die Tonalität dieser Beiträge zu liefern.
Man nehme dazu ein Wörterverzeichnis, ergänze es um ein paar Ausdrücke, gleiche die Kommentare an den hinterlegten Variablen ab und voilá: Die Maschine spuckt aus, wie viel Prozent der Beiträge positiv, negativ oder für die entsprechende Suchanfrage belanglos ist.
Grenzen der Automatisierung
Ein Blick in die Daten bringt jedoch Ernüchterung. Zunächst ist die Vielfältigkeit der deutschen Sprache seit Jahren die größte Herausforderung an automatische Indexierungs- und Tonalitätsverfahren.
Des Weiteren stellt das Web 2.0 diese Auswertungsmethode vor die aktuell unlösbare Aufgabe, dass Beiträge selten grammatikalischen Formen, geschweige denn der deutschen Rechtschreibung genügen. Weiterhin haben automatische Indexierungsverfahren zur Erschließung von textuellen Beiträgen – wie Büchern, Zeitschriften und wissenschaftlicher Literatur – an sich schon mit einer Vielzahl von Problemen zu kämpfen. So sind die Synonymerkennung, die Zerlegung der Komposita und die Stopworteliminierung nur eine Auswahl der Herausforderungen an diese Systeme. Texte aber automatisiert zu verstehen, um sie daraufhin bewerten zu können, stellt die Wissenschaft vor noch ganz andere Hürden.
Emotionen als Herausforderung
Das Social Web ist voller Emotionen und leider verfügt der Sentiment Analyser nur über wenig Sentiment. Als veranschaulichendes Beispiel soll hier der ironische Text aus der Abbildung dienen:
OMFG!!!!!!!!! Ich tweete von einem IPAD!! Scheisse ist das teil geil! Ich hyperventiliere!! Ganz grosses HABENWILL!!!JETZT !!!!!!!
Die Beschreibung des Aufbaus einer Sentimentanalyse lässt beim Leser zunächst einen positiver Eindruck erwarten. Dieser dauert aber nur so lange an, bis ihm die Ironie der Aussage deutlich wird. Der Leser entwickelt innerhalb des Leseprozesses ein Gefühl für den Text. Genau hier liegt schon das erste grundlegende Problem von Sentimentanalysen. Eine Maschine fühlt nicht und ist, ähnlich wie kleine Kinder, nicht in der Lage, Ironie zu erkennen. Sogenannte Emoticons (Smilies usw.) tragen deshalb zu einer Sinngestaltung bei und müssen zugeordnet werden.
Ausdrücke wie zum Beispiel „Scheiße ist das geil“ sind ebenfalls in sich ironisch. Diese erschweren die Auswertungsprozesse um den Faktor X. Unabhängig davon, wie groß das angeschaltete Wörterbuch ist, es wird nicht vollständig sein und schon gar nicht alle Wortkombinationen, die sowohl negativ als auch positiv besetzt sind, in einer sinnvollen Aneinanderreihung abbilden können.
Allein der Ausdruck geil beinhaltet in sich eine hohe Anzahl verschiedener Kombinationen. Wurden die Beiträge zudem noch um Stoppwörter reduziert, ist es schlichtweg unmöglich, einen sinnvollen Zusammenhang herzustellen. Ist dem nicht so, ist der Datenbestand extrem hoch. Wird davon ausgegangen, dass die Beiträge in ihrer ursprünglichen Form zur Verfügung stehen, existieren bei der Auswertung von Wortkombinationen weitere Probleme. Was passiert zum Beispiel, wenn die beiden Begriffe in zwei unterschiedlichen Sätzen stehen? Ist das Ergebnis dann lösungsneutral? Oder wird ein Ausdruck stärker gewichtet als der andere? Natürlich ist die Einstufung immer vom Zusammenhang abhängig. Nur wenn ein Rechner in ausreichendem Maße Zusammenhänge erkennen würde, hätten ein paar Stichpunkte ausgereicht und eine Rückwärtsanalyse hätte diesen Beitrag verfasst.
Das Unmögliche einmal angenommen: Sämtliche Begriffe, Wortkombination und Sinnausdrücke sind in einer Datenbank hinterlegt und alle erdenklichen Rechtschreibformen und -unformen enthalten. Ignoriert wird, dass Unmengen an Ressourcen benötigt werden, um dieses Unterfangen anzulegen, es zu pflegen und zu unterhalten. Werden alle diese Voraussetzungen erfüllt, so wird ein Beitrag mit dieser Datenbank abgeglichen. Ein Ergebnis wird es jedoch erst nach einer nicht absehbaren Zeitspanne geben, da die Leistungsmöglichkeiten des Systems der Performance Grenzen setzen werden. Bei einer großen Masse an Beiträgen, die von automatischen Systemen ausgewertet werden sollen, gilt somit die Faustformel: Je schneller, desto schlechter.
Der Teufel steckt im Detail
Des Weiteren macht es auch nur Sinn, vorher bereinigte Daten zu beurteilen. Ein Beispiel: Im Forum gofeminin wird eine Vielzahl von Themen von einer attraktiven Zielgruppe besprochen. Nun soll anhand eines automatisierten Verfahrens herausgefunden werden, wie die Stimmungslage zur Victoria Versicherung ist. Neben der Victoria Versicherung wird in diesem Forum aber auch noch Victoria Beckham und das Modelabel Victoria Secrets besprochen. Wird eine Bereinigung der Datenquelle unterlassen, machen die Beiträge zu den letzteren beiden Victorias das Ergebnis unbrauchbar, da die reine Wortkombination Victoria Versicherung höchst selten von den Usern ausgeschrieben wird. Die Auswertung von Beiträgen wie zum Beispiel „Meine Tochter Victoria ist bei der Allianz versichert. Die haben ihr ordentlich Probleme gemacht“ macht eine vorherige Bereinigung ebenfalls nötig.
Darüber hinaus ist der Threadverlauf ein Indikator, welcher in der semantischen Analyse nicht zu vernachlässigen ist. Dabei stellt sich die Frage, ob der gesamte Thread, das heißt jeder einzelne Beitrag, bewertet wird oder nur das Ausgangsposting. Wird nur der eröffnende Beitrag bewertet und dieses Ergebnis auf alle anderen Beiträge vererbt, besteht zum einen die Möglichkeit, dass im Verlauf des Threads die Bewertung gegenteilig ausfällt, zum anderen ist es aber auch mitunter so, dass die eigentliche Fragestellung gar nicht mehr berücksichtigt wird.
Datenqualität ist entscheidend
Die Datenbasis ist somit ein entscheidender Faktor zur Bewertung von Beiträgen nach Tonalität. Nur eine ausreichend bereinigte Datenbank ermöglicht qualitativ akzeptable Daten. Deshalb empfiehlt es sich, Anbieter dieser Lösungen explizit mit diesen Fragestellungen zu konfrontieren. Jeder seriöse Anbieter wird seine Vorgehensweise in Hinblick auf diese Fragestellungen erklären und sagen können, welche Fehlerquote auf Grundlage der ausgewählten Datenbasis zu erwarten ist. Auf dieser Grundlage sollte entschieden werden ob der Anbieter, bzw. das Ergebnis, für den eigenen Gebrauch akzeptabel ist.
Zudem werden Lösungen vorgestellt, in denen im Ergebnis die Häufigkeit von Begriffen angezeigt wird, die im Zusammenhang mit einem Produkt oder Unternehmen genannt werden. Dies gibt im besten Fall eine Übersicht über Themen, die mit der Ausgangsfragestellung verwandt sind, jedoch fehlt hier der inhaltliche Bezug. Erst über diesen wird der semantische Zusammenhang, der zur Interpretation und Weiterverarbeitung der Daten nötig ist, dargestellt.
Innerhalb der Webmonitoring Anbieter hat unter anderem infospeed die unterschiedlichen Herausforderungen erkannt und bietet an, das Ergebnis einer automatischen Analyse um die Anreicherung intellektueller Auswertungen zu erweitern. Mit dieser hybriden Methode besteht nicht nur die Möglichkeit, die Stimmungslage im Web zu erfassen, sondern auf Grundlage dieser Daten auch spezifische Rückschlüsse auf die Meinungsbildung zuzulassen. Dazu wird neben der automatischen Auswertung eine intellektuelle Bewertung der Ergebnisse durch ausgebildete Researcher vorgenommen. Im Ergebnis wird somit dargestellt, was User kritisieren oder loben. Zudem werden gezielte Fragestellungen explizit beantwortet und schaffen damit einen reellen Mehrwert für die Weiterverarbeitung und Handlungsableitung aus den Daten. Trotz der vielfältigen, zum Teil ungelösten Problemstellungen existiert eine Vielzahl von Anbietern automatischer Auswertungen. Diese Verfahren seien zwar von der Wirtschaft ausdrücklich gewünscht, was aber nicht heiße, dass diese auch hinreichend umsetzbar seien, gibt Professor Dr. Klaus Lepsky, der an der Technischen Hochschule Köln an Verfahren zur linguistischen Erschließung von Texten forscht, zu bedenken.
Eine der zentralsten Fragen bei dem Vorhaben, mit automatischen Analysen zu arbeiten, ist somit der Qualitätsaspekt. Das heißt, wie hoch die Akzeptanz bei auftretenden Fehlern ist und was an falschen Ergebnissen toleriert werden kann.Da dies in der Summe in den meisten Fällen viele sein werden, eignet sich eine Sentimentanalyse bestenfalls zu einer Trenddarstellung. Es empfiehlt sich also, den Mehrwert einer Sentimentanalyse in Hinblick auf das damit angestrebte Ziel zu überprüfen.








